Welcome back to the world of data modernization! In our previous post on data modernization, we discussed the challenges that banks and financial services (BFS) organizations face in this age of big data, the limitations of legacy data systems, and how a well-laid out data strategy roadmap can help the BFS sector overcome these hurdles. In this article, we will take you through the key elements of building a successful data strategy. To begin, let’s explore each of these elements in more detail and understand how a systematic data modernization approach can help organizations leverage data more efficiently to achieve ‘’Single view of the customer’’, higher ROI, and long-term success.
8 Essential Elements of a Successful Data Modernization Strategy Roadmap
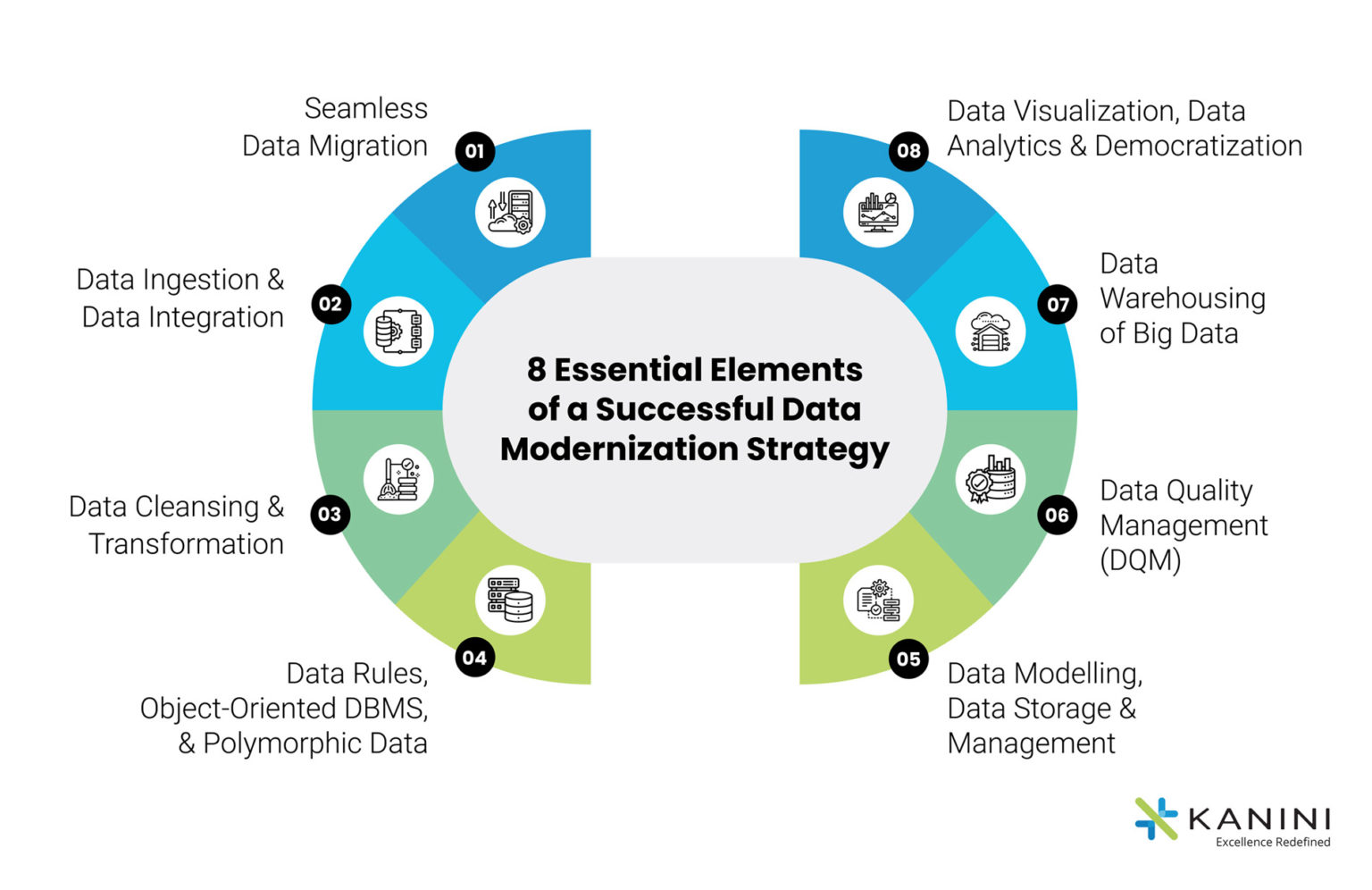
1. Seamless Data Migration
Moving all your data from legacy databases to a modern data infrastructure is what data migration is all about. A robust data migration strategy ensures a seamless transition of clean data from old to a new and modern data platform with no or minimal business disruption. A better data storage and management system that is cost-efficient, scalable, and centrally accessible is what the financial services sector needs today to deliver the expected levels of customer experience. And this is where the cloud comes into the picture. Offering a host of advanced, technology-driven, and more importantly technology-compatible advantages, cloud data platforms are the present and the future of the financial services industry when it comes to migrating to a modern data infrastructure.
Data migration is considered one of the most challenging steps in the entire data modernization journey. But it’s worth it. Once you manage to get through this step, consider half the battle won.
2. Data Ingestion and Data Integration
Data Integration using legacy methods comes with challenges such as a large volume of data, diverse data, time-consuming and resource intensive processes. With a well-planned data strategy roadmap and the implementation of the right Extract, Transform, and Load (ETL) tools to load the data onto the cloud, the Data Integration process can be made much faster and scalable to set you ahead in the competition. Advanced data integration solutions that enable automated, real-time integration of data empower financial services organizations to offer more innovative and reactive services to keep customers satisfied.
3. Data Cleansing and Transformation
Data is considered one of the most valuable business assets today. But not all data is gold. Only that data, which is correct, complete, consistent, and characterized is what you as a financial services organization should be looking out for. And to ensure that you get your hands on this golden data, you need a robust Data Cleansing and Data Transformation process. If you are looking to embrace AI/ ML strategy to improve your business performance, cleansing all datasets becomes the foundation of your digital transformation strategy.
Data Cleansing involves inspecting and addressing inconsistencies in the large volume of data ingested and integrated, filtering out irrelevant data, and creating a pool of meaningful data that is converted into one desired format that is compatible with your data analysis platform.
4. Data Rules, Object-Oriented DBMS, and Polymorphic Data Store
As mentioned earlier, it is the quality of your data and not the volume that is important. A rules-based approach to validating data is an integral part of data quality management. A data rule defines the logic that you want to apply to the data during a task and this systematic approach yields better quality data as compared to an unstructured approach.
Sometimes this data may be represented and stored as objects using an object database management system (ODBMS). Polymorphism is a critical characteristic of an object-oriented database, defined as the capability of an object/data to take multiple forms. Polymorphism allows the same code to work with different types of datasets for data analysis.
Looking for expert guidance in creating a successful data modernization strategy?
5. Data Modelling, Data Storage, and Data Management
Banks and financial services institutions collect a lot of data from customers’ online/ offline transactions, social engagements and interactions, feedback, surveys, and more. Data Modelling is the process of creating an illustrated model of this data to denote its attributes, establish relationships between data items, identify constraints and define the business logic or context to manage the data.
Data Modelling can be performed easily with the help of various commercial and open-source software solutions available in the data market today. There are 3 types of data models – conceptual, logical, and physical data models – and various data modeling techniques are adopted in the process.
Next, what are Data Storage and Data Storage Management?
As your organization grows, the volume of data also increases. A well-laid-out data storage management plan, driven by revolutionary technologies such as AI, removes the snag of having big data stashed across multiple systems with users creating multiple copies (not ideal) and empowers BFS organizations to store data efficiently, securely – in compliance with the laws, makes the data easy to find, access, share, process and recover if lost.
Depending on your end objective, you can choose from the many data storage tools and technologies and virtual environments which can be on-premises (data stored in local hardware and computer memory), cloud (online data storage using SSDs and flash drive arrays) or hybrid (data storage system combining on-premises and cloud).
6. Data Quality Management (DQM)
DQM combines the right people, processes, and technologies to achieve end business goals through data quality improvement. Setting the criteria for high-quality information, sorting through the data collected, and developing strategies to eliminate low-quality data – this is all a part of the Data Quality Management process.
Why is DQM important?
To ensure that only valid data is collected through a united data framework since poor data quality can result in poor business decisions, costing lost time, money, productivity, and reputation.
According to research by Gartner, “the average financial impact of poor data quality on organizations is $12.9 million per year.” IBM also discovered that in the US alone, businesses lose $3.1 trillion annually due to poor data quality!
What does a robust DQM framework need?
- A team to strategize and define the DQM objectives
- Another team to chalk out challenges and choose the right data analytics tools
- A technical team to organize and manage operations
- A cross-functional team of Data architects, Solution Architects, Engineers, and Testers
- An experienced team of experts who can recognize data quality issues and validate data based on accuracy, consistency, relevancy, totality, and timelines
- AI-Powered Analytics tools and solutions to reach the end DQM goals, set KPIs and track progress
Steps in DQM, at a glance
- Data Quality Analysis
- Data Profiling
- Understanding Data Metrics and Quality Criteria
- Setting Data Standards, Management Rules, and Creating Data Policies
- Data Monitoring and Continuous Updates
And, what drives DQM processes?
Technology – AI/ML-driven data analytics solutions to transform vast volumes of data into trusted business information; prevent the negative impact of bad data by consistently learning data metrics’ normal behavior and sending anomaly alerts on bad data discovery.
7. Data Warehousing of Big Data
- Integrated – Enables you to integrate data from disparate sources
- Time variant – Enables you to do a time-based data analysis
- Non-volatile – Once data enters the data warehouse, it stays that way without changing
- Subject-oriented – Built to serve a specific function
With the advent of new technologies and big data (structured and unstructured) flowing in every millisecond, there are various data warehouse designs and data warehousing technologies like Data Lake, Data Vault, and further Data Mart which can be used to serve the financial services sector efficiently. To design a data warehouse, it is vital for the BFS organization to first understand the end use of the data before anything else.
8. Data Visualization, Data Analytics & Democratization
Data Visualization is the pictorial/ graphical representation of data in a way that the organization can draw inferences to drive a business decision or resolve a problem. Various technology-driven tools like Superset, Tableau, Power BI, and more are used for Data Visualization to help a BFS in the following ways –
Data Analytics is involved in every dimension of the banks and financial services sector – whether it is for enhancing customer experience, upselling/cross-selling products, exploring market opportunities, identifying target audience for specific campaigns, managing operations (operational analytics), managing risks (risk analytics), budgeting and forecasting (business analytics), understanding costs (cost benefit analytics) and more.
Data Democratization is what makes accurate data accessible across the organization for actionable insights. Data Governance is an important dimension of Data Democratization that ensures the data being accessed is in line with all data security/privacy protocols through a technology-driven framework.
Thinking Ahead
Identifying why you need the data is the first step in building a successful data strategy. Having the right mix of advanced tools and technologies to drive your data strategy comes next. And the knowledge, expertise, and experience of knowing which tool or technology to use and when to drive the business forward is the third and most vital step.
A robust data strategy that is modern, aligned to the core business strategy, and powered by the right technology and AI-driven tools, is what enables banks and financial institutions to optimize the use of good data to meet their business goals far more efficiently – faster time to market while ensuring a hundred percent data security.
KANINI is a digital transformation enabler, specialized in data analytics and AI, to drive growth for your business. If you are a financial services organization looking to modernize your data strategy roadmap, we have the right expertise and experience to guide you in your journey. Get in touch today!
Author

Anand Subramaniam
Anand Subramaniam is the Chief Solutions Officer, leading Data Analytics & AI service line at KANINI. He is passionate about data science and has championed data analytics practice across start-ups to enterprises in various verticals. As a thought leader, start-up mentor, and data architect, Anand brings over two decades of techno-functional leadership in envisaging, planning, and building high-performance, state-of-the-art technology teams.